Feature Engineering
This service is a building block of data science–the goal is to normalize data by minimizing errors and fixing any potential problems. Feature Engineering can be performed exclusively or as part of Exploratory Data Analysis. The following reports are examples of Feature Engineering.
Binning Data
Binning is the process of converting a continuous variable into a set of ranges and then treating these ranges as categories. This process is widely known for improving predictive power and for reducing the complexity of a variable.
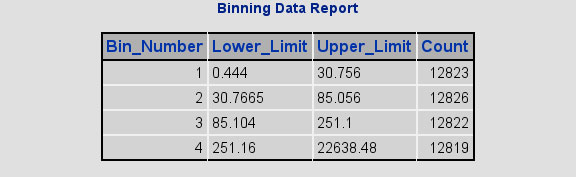
click to view larger
Changing Data Distribution
Changing a variable distribution is the process of replacing the variable values with their ranks. This can result in a significant change in model performance and reveal relationships that were masked by the variable distribution.
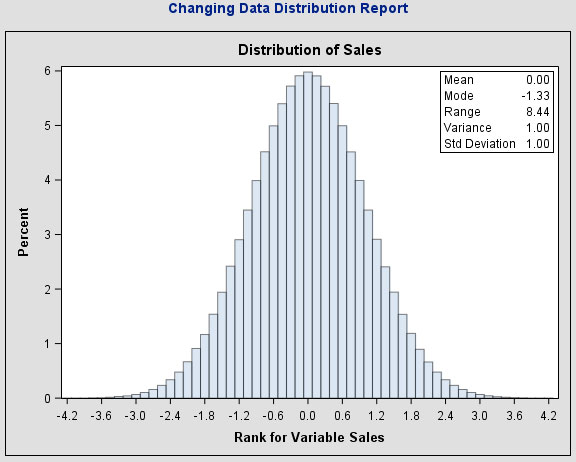
click to view larger
Creation of New Variables
This process uses different mathematical formulas to create new variables from existing ones. Each mathematical expression offers the use of a set of equation forms, such as polynomials, products, and divisions. This process is key to success in applied machine learning.
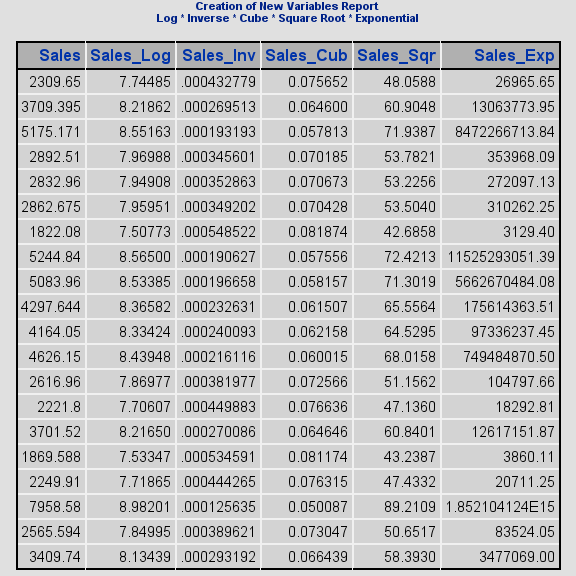
click to view larger